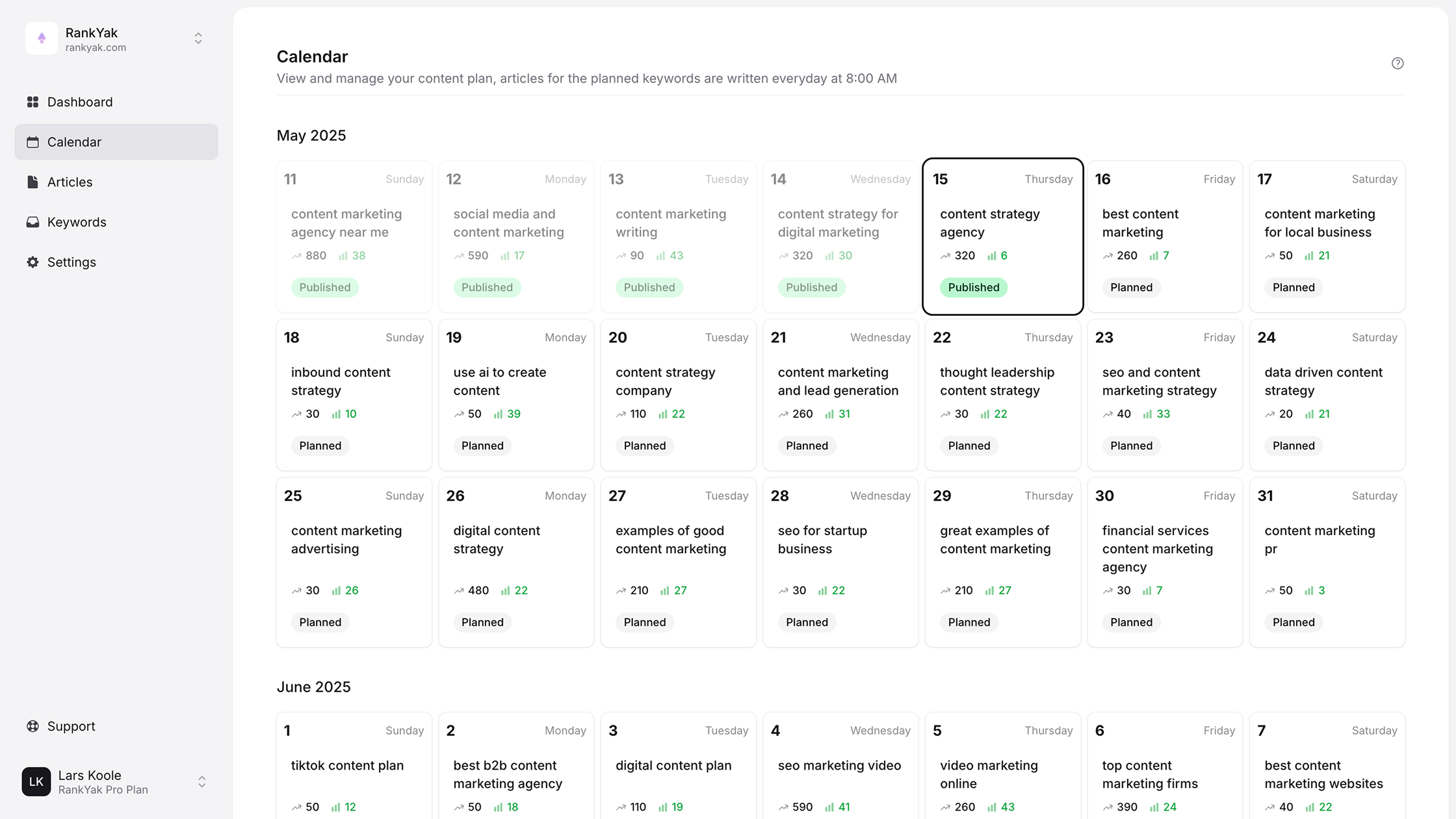
Robots.txt Generator
Create a properly formatted robots.txt file to control how search engines crawl your website. Add rules for different user-agents, specify allowed and disallowed paths, and include your sitemap.
Crawl Rules
Optional: Include your XML sitemap location
Optional: Delay between crawler requests (not all bots honor this)
# Add rules above to generate robots.txt content
Save this content as robots.txt in your website's root directory.
How to Use This Tool
- Add crawl rules - Click "Add Rule" to create rules for different user-agents. The default rule (*) applies to all search engine bots.
- Configure directives - For each rule, add Allow or Disallow directives to control which paths can be crawled. Use "/" to affect all paths or specific paths like "/admin/".
- Add your sitemap - Enter your XML sitemap URL to help search engines discover all your pages.
- Set crawl delay - Optionally specify a delay between requests to reduce server load (note: not all bots honor this).
- Copy and deploy - Copy the generated content and save it as robots.txt in your website's root directory (e.g., https://example.com/robots.txt).
Why Robots.txt Matters for SEO
The robots.txt file is a critical part of technical SEO. It tells search engine crawlers which pages they can and cannot access on your website, helping you control your crawl budget and protect sensitive areas.
- Crawl budget optimization: Block search engines from wasting resources on unimportant pages (admin areas, duplicate content, staging environments).
- Prevent indexing issues: Stop search engines from crawling pages that shouldn't appear in search results, like login pages or internal search results.
- Server load management: Use crawl-delay to reduce the impact of crawler traffic on your server.
- Sitemap discovery: Point crawlers to your XML sitemap so they can efficiently find and index your content.
- AI bot control: Block AI training bots (GPTBot, CCBot, etc.) if you don't want your content used for AI training.
Common Robots.txt Patterns
User-agent: * Disallow: /
Blocks all bots from your entire site. Use for staging sites.
User-agent: * Disallow: /admin/ Disallow: /wp-admin/
Prevents indexing of administrative sections.
User-agent: * Allow: / Sitemap: https://example.com/sitemap.xml
Allows full access with sitemap reference.
User-agent: GPTBot Disallow: / User-agent: CCBot Disallow: /
Prevents AI training bots from scraping your content.
Frequently Asked Questions
The robots.txt file must be placed in the root directory of your website and accessible at https://yourdomain.com/robots.txt. Search engines will only look for it at this exact location - placing it in a subdirectory won't work.

Get Google and ChatGPT traffic on autopilot.
Start today and generate your first article within 15 minutes.
SEO revenue calculator
How much revenue is your website leaving on the table?
Take a quick quiz and see exactly how much organic revenue you're missing out on, along with personalized tips to fix it.
-
4 questions, under 1 minute
-
See traffic and revenue potential
-
No email required
Free · takes 1 minute · no signup needed
Question 1 of 4
Question 2 of 4
Question 3 of 4
Question 4 of 4
Your SEO growth potential
Extra visitors / month
after 6-12 months of consistent publishing
Revenue potential / year
at your niche's avg. conversion rate
Articles needed (12 mo)
to reach this traffic level
ROI with RankYak
at $99/mo ($1,188/year)
To hit that number, you'd need to:
- Build a topical authority strategy for your niche
- Research keywords & map out a full topical cluster
- Write, edit & publish an article every single day
- Build backlinks to the articles you publish
RankYak handles all of this automatically, every day.
* Estimates based on industry averages. Results vary by niche, competition, and domain authority. Most SEO results become visible after 3-6 months of consistent publishing.