Semantic SEO Automation: Workflows To Scale Authority Fast

Building topical authority used to mean months of manual keyword mapping, spreadsheet gymnastics, and hoping your internal links actually made sense to Google. Semantic SEO automation changes that equation entirely, replacing tedious, error-prone workflows with systems that handle topic clustering, entity research, and content optimization at a pace no human team can match alone.
The concept goes beyond simply "using AI to write articles." It's about structuring your entire content strategy around how search engines actually understand topics, through entities, relationships, and context, and then automating the execution of that strategy so you're not stuck doing it piece by piece. For businesses trying to compete on organic search without a dedicated SEO department, this is where things get practical. Tools like RankYak are built around this exact principle: automating the full content lifecycle, from discovering semantically relevant keywords to publishing optimized articles with proper internal linking and topic cluster architecture, every single day.
This article breaks down what semantic SEO automation actually means, walks through the core workflows you can automate (topic clustering, entity mapping, internal linking, content optimization), and shows you how to scale topical authority without scaling your headcount. Whether you're running a single site or managing several, you'll walk away with a clear picture of which tasks to automate and how to set up workflows that compound over time.
What semantic SEO automation is
Semantic SEO is the practice of building content around topics, entities, and their relationships rather than isolated keyword phrases. Search engines like Google no longer just match words on a page to words in a query. They map out what things are, how they connect to each other, and whether your site covers a subject comprehensively enough to deserve authority status. Semantic SEO automation, then, is the use of tools and systems to execute that entire strategy at scale, from identifying entity gaps in your niche to generating content that fills them, without requiring you to tackle each step by hand or maintain a spreadsheet the size of a small novel.
How search engines read meaning
Google's understanding of the web is built on structured knowledge that includes the connections between named entities: people, places, products, brands, and concepts. When you publish a page about "espresso machines," Google does not just see those two words in isolation. It recognizes that espresso machines relate to coffee, brewing methods, grind size, and specific brands, and it expects a truly authoritative site to address those related topics with depth and consistency. This shift toward entity-based understanding is what separates semantic SEO from the older approach of targeting a handful of keywords and treating each page as a standalone effort.
The difference between a site that compounds in authority and one that stagnates usually comes down to whether its content signals comprehensive topical coverage, not just keyword frequency.
Your job, from a semantic SEO standpoint, is to map the full landscape of topics in your niche and then publish content that covers them in a structured, interconnected way. Doing that manually across dozens or hundreds of pages is where most teams run out of bandwidth, consistency, and frankly, patience.
The three layers semantic SEO automation handles
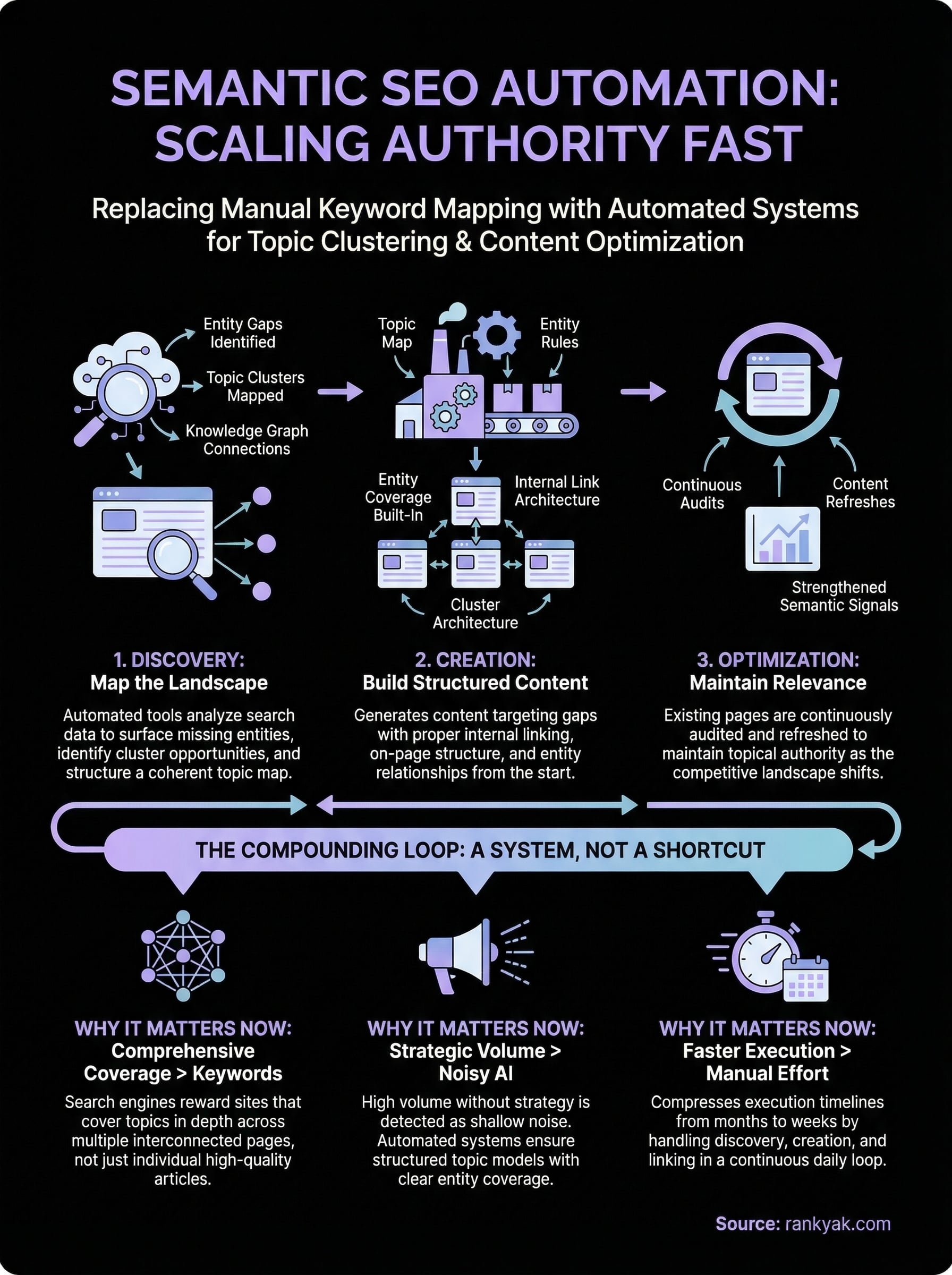
Automation solves the manual bottleneck by operating across three distinct layers simultaneously. The first is discovery, where tools analyze your existing content, competitor sites, and search data to surface the entity gaps and topic clusters you have not yet addressed. The second is creation, where systems generate content that targets those gaps with proper internal linking, on-page structure, and entity coverage built in from the start rather than retrofitted later. The third is ongoing optimization, where your existing pages get audited continuously and refreshed to strengthen their semantic relationships as the competitive landscape shifts around them.
Each layer feeds the next in a compounding loop. Without discovery, you create content without strategic direction and fill your site with pages that do not reinforce each other. Without creation at scale, your topical map stays incomplete and patchy, leaving clear openings for competitors. Without optimization, even your strongest early pages slowly lose relevance as new content enters the space. Semantic SEO automation connects all three into one continuous workflow, which is the kind of system that builds measurable authority over months rather than years of grinding manual effort.
Why this is not just AI content generation
Many people conflate semantic SEO automation with simply using AI to write more articles faster. That framing misses the point entirely. Bulk AI writing without a strategic framework produces pages that do not support each other, do not cover the right entities in the right depth, and do not send coherent topical signals to search engines. True semantic SEO automation starts with a structured topic model and uses that model to direct what gets written, how pages link together, which entities need coverage, and in what order to build cluster authority. The output may look similar on the surface, but the underlying architecture and intent are completely different from just generating text and publishing it.
Think of it this way: a pile of bricks is not a building. Strategic automation provides the blueprint, the sequencing, and the quality checks that turn individual content pieces into a coherent structure that search engines can recognize as authoritative.
Why semantic SEO automation matters now
The search landscape has shifted in ways that make manual semantic SEO increasingly hard to sustain. Google's ranking systems now process queries with a level of contextual understanding that rewards comprehensive topic coverage over simple keyword repetition. At the same time, the sheer volume of content competing for every niche has grown dramatically, and that combination of smarter algorithms and higher content volume means that slow, piecemeal approaches to building authority are no longer keeping pace with what it takes to rank.
Search engines reward topical depth, not just page quality
Google's systems are built to identify whether your site covers a subject comprehensively across multiple interconnected pages, not just whether a single page is well-written. If your competitor publishes thirty interconnected articles on coffee brewing and you publish five, their topical signal is stronger regardless of how polished your individual pages are. Closing that gap by hand, one page at a time, takes time most businesses cannot spare.
The sites pulling away in organic search right now are not necessarily producing better individual articles; they are producing more complete topic maps, faster.
Semantic SEO automation gives you a practical way to close topical gaps at a pace that matches how competitive your niche actually is, rather than the pace your available hours allow.
AI-generated content has raised the volume bar
Your competitors are already using AI to produce more content. That alone forces a response, but the bigger issue is that volume without strategy creates noise rather than authority. Sites flooding search results with loosely related articles, no clear topic clusters, and weak internal linking are not actually gaining ground in rankings, because search engines detect shallow topical coverage even when the word count is high. The sites winning are using automation strategically, which means using systems that build structured topic models and generate content that fills specific entity gaps in a coherent order.
Speed of execution now determines competitive position
In most niches, the window for establishing topical authority on an emerging subject closes quickly. Semantic SEO automation compresses your execution timeline from months to weeks by handling discovery, content creation, and internal linking in a continuous loop. If you are still building topic clusters manually, you are making decisions about which pages to create, in what order, one at a time. That approach cannot match a system that identifies gaps and fills them daily without waiting for your next available block of time.
The building blocks of semantic SEO
Before you can automate anything effectively, you need a clear picture of what semantic SEO is actually made of. Each component plays a specific role in how search engines assign topical authority to your site, and understanding those roles tells you exactly which parts of the workflow are worth automating first.
Topic clusters and pillar pages
A topic cluster is a group of interconnected content pieces that collectively cover a subject from multiple angles. At the center sits a pillar page, which provides broad coverage of the main topic. Surrounding it are cluster pages that go deeper into specific subtopics, each linking back to the pillar and to related cluster pages. This structure sends a clear signal to search engines that your site covers the subject with enough depth and breadth to deserve authority status.

A well-built topic cluster does more for your rankings than ten isolated articles targeting individual keywords, because it establishes the site-wide topical signal search engines are looking for.
Without a deliberate cluster architecture, your pages compete against each other, confuse search engines about which page should rank, and fail to reinforce your overall topical coverage. Semantic SEO automation helps by mapping these clusters systematically and ensuring every new article fits into an existing structure rather than floating on its own.
Entities and their relationships
An entity is any distinct, identifiable concept that a search engine can recognize and categorize: a brand, a person, a product, a process, a location. When Google processes your content, it identifies the entities present and checks whether the relationships between them match what it already knows from its knowledge graph. Pages that accurately reflect those relationships in their content, structure, and linking patterns get scored as more contextually relevant.
For your site, this means covering the right entities in the right context, not just mentioning keywords. If you publish content about project management software, covering related entities like team collaboration, task dependencies, and resource allocation strengthens your topical signal far more than repeating the phrase "project management software" throughout the page.
Internal linking architecture
Internal links are the connective tissue of semantic site structure. They tell search engines which pages are related, which are most important, and how your content clusters are organized. Poor internal linking leaves pages isolated, which limits how much authority flows across your site even when your individual articles are strong. A consistent internal linking strategy that connects cluster pages to pillars and to each other is one of the highest-leverage parts of semantic SEO automation to get right early.
How to build semantic SEO automation step by step
Building a semantic SEO automation system does not require a team of engineers. You need a clear sequence of steps that turns your niche into a structured topic map and then keeps that map growing through automated content production. Getting the sequence right matters: if you skip the foundation and jump straight to generating content, you end up with a pile of articles that do not reinforce each other.
Start with a topic map, not a keyword list
A keyword list tells you what phrases people search. A topic map tells you how subjects connect and which clusters of content you need to build to cover your niche comprehensively. Start by identifying your core subject and then branch outward into the subtopics, entities, and related concepts that surround it. Tools that pull from search data and knowledge graphs can surface these connections automatically, but the key output you want is a structured cluster architecture: a set of pillar topics, each with a defined set of cluster pages assigned to them.
Your topic map is the blueprint for every piece of content you produce; building it first saves you from publishing pages that work against each other.
Once your map exists, prioritize clusters by business relevance and competitive gap. Start with the areas where you have some existing content or authority, then fill outward into adjacent topics as your coverage deepens.
Set up your content production pipeline
With your topic map in place, connect it to a content generation workflow that draws from that structure rather than treating each article as a standalone request. This means your system needs to know which cluster a new article belongs to, which pillar it should link back to, and which related entities it should cover. Define those rules once and let the pipeline apply them automatically to every article it produces.
Your pipeline should also handle publishing and scheduling so content goes live consistently without you manually pushing it through each time. Consistency matters for semantic authority because search engines register your topical coverage over time, not just from a single publication burst.
Wire in internal linking from day one
Internal linking is the step most teams skip during setup, then spend months fixing later. Build your linking rules directly into your production workflow so every new article automatically connects to its pillar page and to the most relevant cluster pages already on your site. Automating this at creation time is far more reliable than running audits afterward and manually inserting links across hundreds of published pages.
High-impact workflows to automate first
Not every part of your SEO workflow delivers equal returns when automated. Some tasks compound in value quickly because they directly affect how search engines map your topical authority; others are useful but not urgent. When you are setting up semantic SEO automation for the first time, focusing on the workflows below first gets you the fastest, most measurable gains with the least risk of structural problems down the line.
Topic cluster gap detection
Your most valuable early automation task is identifying which subtopics and entities your current content is missing. Rather than auditing pages manually, you can feed your existing URL inventory and core topic list into a tool that maps your current coverage against the full semantic landscape of your niche. What surfaces is a prioritized list of missing cluster pages, which are the exact articles your site needs to fill out its topical signals and stop leaving gaps that competitors can occupy.

Running this detection on a recurring schedule matters as much as the initial audit. New entities and subtopics enter your niche constantly, and a one-time gap analysis becomes stale within weeks.
Internal link insertion at scale
Once your content production pipeline is running, internal link management becomes the most labor-intensive bottleneck if you handle it manually. Every new article needs outbound links to its pillar and to relevant cluster pages, and every existing article that covers related entities should point to the new one. Doing that by hand across even fifty pages is error-prone and inconsistent.
Automating internal link insertion at the point of creation is far more reliable than auditing and patching links across hundreds of published pages after the fact.
The right approach is to define linking rules based on your topic cluster map and let your system apply them automatically when each article is generated or published. This keeps your site's linking architecture consistent and prevents the isolated pages that weaken topical authority signals over time.
Content refresh scheduling
Existing pages lose relevance as new content enters your niche and entity relationships in search engine knowledge graphs evolve. An automated refresh workflow monitors your published pages against current search data and flags articles that have dropped in coverage quality or ranking position, then queues them for updates without requiring you to track each page manually.
Prioritize refreshing pillar pages and high-traffic cluster pages first, since those carry the most authority and the most risk if they go stale. Keeping them updated on a defined cycle maintains your topical foundation as your overall content footprint grows.
Quality control and measurement that prevent drift
Semantic SEO automation scales your output, but it introduces a new risk: your content strategy can drift quietly off course if you are not measuring whether your automated workflows are actually building authority, not just publishing volume. Setting up clear measurement checkpoints prevents you from running a system for months only to discover it has been filling topical gaps in the wrong priority order or generating pages that do not connect back to your core clusters.
Metrics that tell you if your topic clusters are working
You need two categories of metrics to evaluate cluster health. The first is topical coverage progress: the percentage of planned cluster pages that are live, the number of entities covered per cluster, and whether each pillar page has enough supporting cluster pages linked to it. The second is traffic and ranking signals per cluster: rather than measuring individual page performance, group your pages by cluster and look at aggregate organic impressions, clicks, and average position. A cluster gaining consistent ranking movement signals that your semantic signals are landing. A cluster stagnating despite new content usually points to weak internal linking or missing entity coverage.
Measuring at the cluster level instead of the page level gives you a far more accurate picture of whether your topical authority strategy is working.
Track these cluster-level metrics on a fixed cadence, weekly for fast-moving niches, monthly for more stable ones. If a cluster is not gaining traction after a defined period, that is your signal to audit the internal linking structure and entity coverage before producing more content for it.
Setting thresholds before drift becomes a ranking problem
Drift happens gradually, which makes it easy to miss until your rankings have already slipped. The fix is to define thresholds in advance rather than reacting after the fact. Set a minimum acceptable internal link count for each new published article. Define a maximum acceptable time between content refreshes for your highest-traffic pillar pages. Specify the number of entity mentions a cluster page needs to cover its subtopic adequately.
Once you establish these thresholds, your measurement workflow becomes a systematic check against defined standards rather than a subjective review. Feed these outputs into a shared dashboard that your team checks on a regular schedule, so no one has to remember to audit manually. This turns quality control from an occasional project into an ongoing, automated guardrail that keeps your content architecture coherent as your site scales.
Quick wrap-up
Semantic SEO automation works when you treat it as a system, not a shortcut. You build a structured topic map, connect it to a content production pipeline, automate internal linking from the start, and measure performance at the cluster level rather than the individual page level. Each workflow compounds the one before it, which means getting the foundation right early is what separates sites that build authority consistently from those that publish volume and stall out after a few months.
The tools and workflows exist right now to run this entire process without a large team or a complicated tech stack. RankYak handles the full content lifecycle, from keyword discovery and topic clustering to daily article generation and automatic publishing, so your semantic strategy executes on schedule without requiring you to manage every step manually. Start your free trial and see how quickly a structured, automated approach turns into measurable ranking gains.

Get Google and ChatGPT traffic on autopilot.
Start today and generate your first article within 15 minutes.
SEO revenue calculator
How much revenue is your website leaving on the table?
Take a quick quiz and see exactly how much organic revenue you're missing out on, along with personalized tips to fix it.
-
4 questions, under 1 minute
-
See traffic and revenue potential
-
No email required
Free · takes 1 minute · no signup needed
Question 1 of 4
Question 2 of 4
Question 3 of 4
Question 4 of 4
Your SEO growth potential
Extra visitors / month
after 6-12 months of consistent publishing
Revenue potential / year
at your niche's avg. conversion rate
Articles needed (12 mo)
to reach this traffic level
ROI with RankYak
at $99/mo ($1,188/year)
To hit that number, you'd need to:
- Build a topical authority strategy for your niche
- Research keywords & map out a full topical cluster
- Write, edit & publish an article every single day
- Build backlinks to the articles you publish
RankYak handles all of this automatically, every day.
* Estimates based on industry averages. Results vary by niche, competition, and domain authority. Most SEO results become visible after 3-6 months of consistent publishing.